- Published on
مقدمهای بر پایگاه داده برداری
- نویسندگان

- نام
- هومن امینی
- توییتر
- @HoomanAmini
مقدمهای بر پایگاه داده برداری
پایگاه داده برداری، نوع خاصی از پایگاه داده است که برای ذخیرهسازی، فهرستبندی و جستجوی دادههای برداری با بُعد بالا بهینه شده است. پایگاه دادههای سنتی برای مدیریت دادههای ساختاریافته و جدولی طراحی شدهاند، اما برای دادههای غیرساختاریافته مثل تصویر، صدا، ویدئو و متن عملکرد ضعیفی دارند. پایگاه داده برداری این شکاف را پر کرده و امکان جستجوی سریع و دقیق مشابهت را فراهم میکنند و به همین دلیل برای کاربردهای یادگیری ماشین (ML)، هوش مصنوعی (AI)، موتورهای پیشنهاددهنده و پردازش زبان طبیعی (NLP) اهمیت زیادی دارند.
مفهوم بردار و نقش آن در دادههای غیرساختاریافته
در یادگیری ماشین و هوش مصنوعی، دادههای غیرساختاریافته مثل متن یا تصویر به شکل بردارهایی با طول ثابت تبدیل میشوند تا امکان پردازش آسان و سریعتر فراهم شود. بردارها ویژگیهای مهم داده را به صورت عددی نمایان میکنند و ارتباطات و شباهتهای معنایی را حفظ میکنند. به عنوان مثال، در پردازش زبان طبیعی (NLP)، بردارها میتوانند معانی و روابط بین کلمات را به خوبی نمایش دهند. برای مثال، بردار مربوط به کلمه «شاه» میتواند به بردار کلمه «ملکه» نزدیک باشد، یا بردار «تهران» به بردار «ایران» نزدیکتر از سایر بردارها باشد.
یک بردار، مجموعهای از اعداد است که ویژگیهای داده را در فضای بُعدی نشان میدهد. به عبارت دیگر، بردار، نقطهای در یک فضای چندبُعدی است که هر بُعد آن نمایانگر یک ویژگی خاص از داده است. بُعد (Dimension) به تعداد ویژگیهایی اشاره دارد که برای نمایش داده استفاده میشود. به عنوان مثال، اگر بردار یک جمله دارای ۳۰۰ بُعد باشد، هر کدام از این ۳۰۰ عدد میتواند نمایانگر یکی از ویژگیهای معنایی یا نحوی آن جمله باشد.
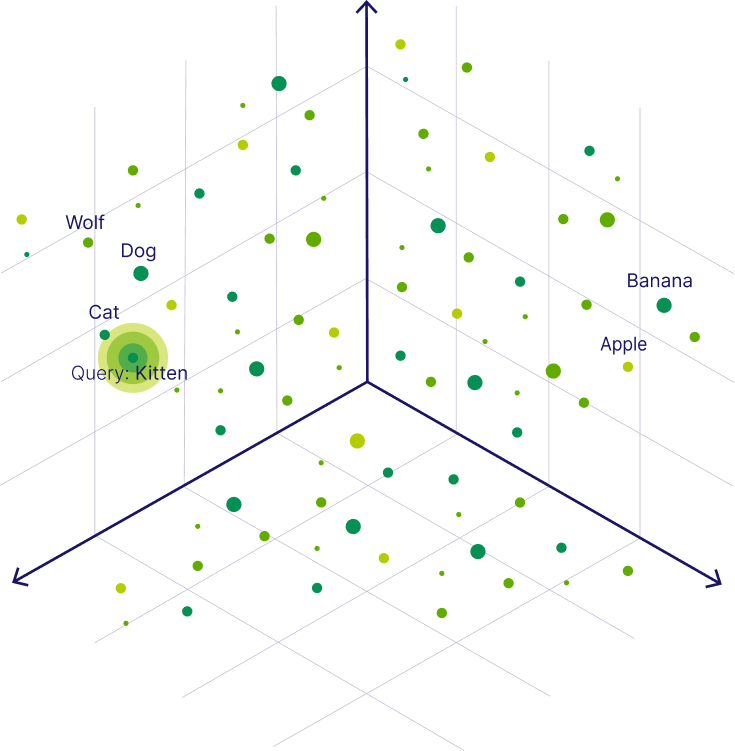
تعبیهها (Embeddings) و ارتباط آنها با پایگاه داده برداری
تعبیهها (Embeddings) بردارهایی هستند که برای نمایش ویژگیهای دادههای غیرساختاریافته به کار میروند. این تعبیهها میتوانند برای نمایش متون، تصاویر، صداها و سایر دادهها استفاده شوند و به طور موثری به بازنمایی اطلاعات به صورت عددی کمک میکنند. تعبیهها به کمک مدلهای یادگیری ماشین تولید میشوند و به طور کلی هر داده را به یک بردار با ابعاد مشخص تبدیل میکنند که روابط معنایی بین دادهها را حفظ میکند.
در پایگاه داده برداری، تعبیهها به عنوان ورودی ذخیره میشوند تا امکان جستجوی سریع و کارآمد مشابهت فراهم شود. به عنوان مثال، در یک سیستم توصیهگر، تعبیههای کاربران و محصولات در پایگاه داده برداری ذخیره میشوند و هنگامی که کاربر به دنبال محصولی میگردد، بردار مشابه با بردار کاربر جستجو شده و محصولات مشابه پیشنهاد میشوند. به همین صورت، در پردازش زبان طبیعی (NLP)، تعبیههای متنی به پایگاه داده برداری وارد میشوند تا جستجوی معنایی و بازیابی اطلاعات بهینه شود.
به طور خلاصه، تعبیهها ابزار اصلی برای تبدیل دادههای غیرساختاریافته به دادههای عددی قابل پردازش هستند که در پایگاه داده برداری ذخیره و مدیریت میشوند. این پایگاه دادهها با استفاده از تعبیهها، قابلیت جستجوی مشابهت، توصیهگری و پردازش کارآمد دادههای پیچیده را فراهم میکنند.
بردارها معمولاً در کاربردهای مختلفی به کار میروند. به عنوان مثال:
- پردازش زبان طبیعی (NLP): کلمات و جملات به بردارهایی تبدیل میشوند که ویژگیهای معنایی آنها را حفظ میکنند. به این ترتیب میتوان مشابهت معنایی بین دو جمله را با محاسبه فاصله بین بردارهای آنها سنجید.
- بینایی ماشین: تصاویر به بردارهایی تبدیل میشوند که ویژگیهای بصری مانند رنگ، بافت، و شکل را نشان میدهند. این ویژگیها به ماشین امکان میدهد تا تصاویر مشابه را شناسایی کند.
- توصیهگرها: کاربران و محصولات به بردارهایی تبدیل میشوند که رفتار و علایق کاربران و ویژگیهای محصولات را نشان میدهند. این بردارها به سیستم توصیهگر کمک میکنند تا محصولات مشابه را به کاربران پیشنهاد دهد.
تفاوتهای پایگاه داده برداری با پایگاه دادههای سنتی
پایگاه دادههای سنتی (مثل پایگاه دادههای رابطهای) دادهها را به شکل ساختاریافته در جدولها ذخیره میکنند و برای جستجوهای دقیق بهینه هستند، اما برای جستجوی مشابهت در دادههای برداری با بُعد بالا مناسب نیستند. پایگاه داده برداری به طور خاص برای این نیاز طراحی شدهاند و ویژگیهای زیر را ارائه میدهند:
- ذخیرهسازی کارآمد بردارها: این پایگاه دادهها بردارهای با بُعد بالا را فشرده و بهینه ذخیره میکنند.
- جستجوی مشابهت: با استفاده از معیارهای مشابهت مثل فاصلهی اقلیدسی یا کسینوس، بردارهای نزدیک به بردار جستجو را پیدا میکنند.
- جستجوی نزدیکترین همسایهها به صورت تقریبی (ANN): برای سرعت بخشیدن به جستجوها، از الگوریتمهای تقریبی استفاده میشود.
- مقیاسپذیری بالا: این پایگاه دادهها به صورت افقی مقیاسپذیر هستند و امکان مدیریت حجم بالای داده را فراهم میکنند.
پایگاه دادههای برداری محبوب
برخی از پایگاه دادههای برداری که بهطور گسترده مورد استفاده قرار میگیرند عبارتند از:
- Pinecone: یک پایگاه داده برداری مدیریتشده که برای مقیاسپذیری و سهولت استفاده طراحی شده است. این پایگاه داده به طور خاص برای جستجوی برداری و پیادهسازی در برنامههای توصیهگر و NLP بهینه شده است.
- Weaviate: یک پایگاه داده برداری متنباز که از جستجوی ترکیبی بردارها و کلیدواژهها پشتیبانی میکند. Weaviate قابلیت اتصال به منابع مختلف داده را دارد و مناسب برای کاربردهای متنوع هوش مصنوعی است.
- Milvus: یک پایگاه داده برداری متنباز که عملکرد بالایی دارد و به خوبی با زیرساختهای ابری و داخلی سازگار است. Milvus از جستجوی سریع برداری و مقیاسپذیری بالا پشتیبانی میکند.
- PostgreSQL + PGVector: PostgreSQL با افزونه PGVector امکان ذخیرهسازی و جستجوی بردارها را در محیطی که برای دادههای ساختاریافته نیز بهینه است، فراهم میکند. این روش برای کاربردهایی که نیاز به استفاده از هر دو نوع داده دارند مناسب است.
کاربردهای اصلی پایگاه داده برداری
پایگاه داده برداری امکان پیادهسازی طیف گستردهای از کاربردهای هوش مصنوعی را فراهم میکنند:
- سیستمهای توصیهگر: با ذخیره تعبیههای کاربران و محصولات، امکان توصیهگری بر اساس مشابهت فراهم میشود.
- پردازش زبان طبیعی (NLP): ذخیرهسازی تعبیههای متنی امکان جستجوی معنایی و بازیابی اطلاعات را فراهم میکند.
- بازیابی تصویر و ویدئو: ذخیره تعبیههای تصاویر و قابهای ویدئویی امکان جستجوی مشابهت را فراهم میکند.
- تشخیص ناهنجاری: با تحلیل بردارهایی که تفاوت قابل توجهی با بقیه دارند، ناهنجاریها شناسایی میشوند.
- پردازش صدا و صوت: ذخیره تعبیههای صوتی امکان تطابق و بازیابی صداها را فراهم میکند.
چالشهای کار با پایگاه داده برداری
پایگاه داده برداری با وجود مزایای فراوان، چالشهایی نیز دارند:
- مدیریت دادههای با بُعد بالا: فهرستبندی و جستجوی کارآمد در فضای با بُعد بالا نیاز به منابع محاسباتی زیاد دارد.
- تقاضای منابع بالا: پایگاه داده برداری نیاز به منابع ذخیرهسازی و پردازش زیادی دارند.
- پیچیدگی در یکپارچهسازی: ادغام این پایگاه دادهها با سیستمهای موجود ممکن است نیازمند مهارتهای خاص باشد.
آینده پایگاه داده برداری
پایگاه داده برداری نقش مهمی در برنامههای هوش مصنوعی دارند و با پیشرفتهای بیشتر، احتمالاً به یکپارچگی بیشتر با چارچوبهای یادگیری ماشین، قابلیتهای پردازش دادههای بلادرنگ و بهبود جستجوی ترکیبی خواهند رسید.