- Published on
معرفی Spring AI (قسمت دوم): بررسی مفاهیم پایه
- نویسندگان

- نام
- هومن امینی
- توییتر
- @HoomanAmini
در قسمت اول این مقاله، با Spring AI و مزایا و ویژگیهای آن آشنا شدیم. حالا در قسمت دوم، قصد داریم به بررسی مفاهیم اصلی و پایهای Spring AI بپردازیم تا درک بهتری از اجزای مختلف آن داشته باشیم. این قسمت به عنوان راهنمایی برای توسعهدهندگانی که میخواهند از Spring AI در پروژههای خود بهره بگیرند، طراحی شده است.
مفاهیم اصلی Spring AI
مفاهیم Spring AI به منظور سادهسازی فرآیند ادغام هوش مصنوعی در برنامهها طراحی شدهاند. این مفاهیم شامل اجزایی است که قابلیت استفاده از مدلهای مختلف هوش مصنوعی و اتصال آنها به دادهها و سرویسهای موجود در برنامههای شما را فراهم میکنند. هدف اصلی این مقاله، توضیح این مفاهیم برای توسعهدهندگان است تا بتوانند به راحتی از این قابلیتها بهرهمند شوند.
مدلهای هوش مصنوعی
مدلهای هوش مصنوعی الگوریتمهایی هستند که برای پردازش و تولید اطلاعات طراحی شدهاند و اغلب عملکردهای شناختی انسان را تقلید میکنند. این مدلها با یادگیری الگوها و بینشها از مجموعههای داده بزرگ، میتوانند پیشبینیهایی انجام دهند، متن تولید کنند، تصاویر ایجاد کنند یا سایر خروجیها را فراهم کنند که باعث بهبود برنامههای مختلف در صنایع گوناگون میشود.
Spring AI از مدلهای متنوعی مانند چتباتها، تبدیل متن به گفتار، تبدیل متن به تصویر و رونویسی صوتی پشتیبانی میکند که میتوانند به راحتی در برنامههای موجود ادغام شوند. همچنین، این پلتفرم با ارائهدهندگان بزرگ مدلهای هوش مصنوعی مانند OpenAI، Microsoft، Google و Hugging Face همکاری میکند که این امکان را به توسعهدهندگان میدهد تا مدل مناسب برای نیازهای خاص خود را انتخاب کنند.
شکل زیر چندین مدل را بر اساس نوع ورودی و خروجی آنها دسته بندی می کند:
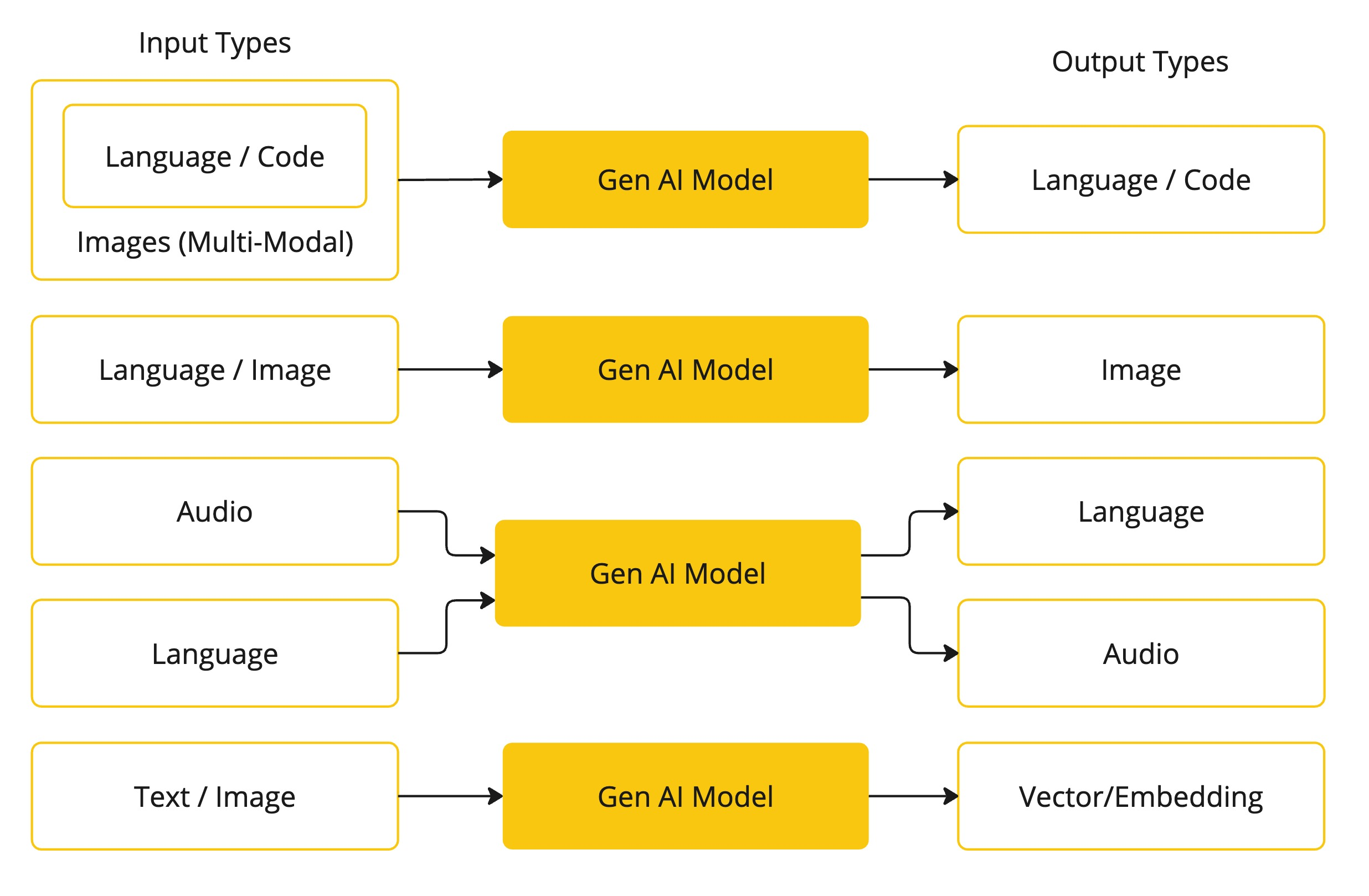
پرامپتها و مهندسی پرامپت
پرامپتها اساس ورودیهای زبانی هستند که مدل هوش مصنوعی را برای تولید خروجیهای خاص هدایت میکنند. پرامپتها میتوانند شامل دستورات، سؤالات یا هر نوع متنی باشند که هدف آن راهنمایی مدل برای تولید پاسخی خاص است. به عنوان مثال، در یک مدل چتبات، پرامپت میتواند سؤال کاربر باشد که مدل باید به آن پاسخ دهد.
پرامپتها نقش مهمی در کارایی مدلهای هوش مصنوعی دارند. اگر پرامپت به خوبی طراحی شود، مدل میتواند نتایج بهتری ارائه دهد. مهندسی پرامپت (Prompt Engineering) به فرآیند طراحی دقیق پرامپتها گفته میشود تا مدل بتواند بهترین خروجی ممکن را تولید کند. ایجاد پرامپتهای مؤثر نیازمند شناخت دقیق از رفتار مدل و تواناییهای آن است.
پرامپتها میتوانند چندین نقش مختلف داشته باشند. به عنوان مثال:
نقش سیستم: این نقش به مدل میگوید چگونه رفتار کند و زمینه تعامل را تعیین میکند. به عنوان مثال، میتواند مشخص کند که مدل باید مانند یک مربی زبان انگلیسی عمل کند.
نقش کاربر: این نقش معمولاً ورودی کاربر است که مدل باید به آن پاسخ دهد.
نقش دستیار: این نقش مربوط به پاسخهای قبلی مدل است که به عنوان مرجع برای تولید پاسخهای جدید استفاده میشود.
ایجاد پرامپتهای مؤثر، هم یک هنر و هم یک علم است. این کار به توسعهدهندگان این امکان را میدهد که با استفاده از زبان طبیعی و به شیوهای مشابه مکالمه با یک انسان، مدل را به بهترین نحو هدایت کنند. به همین دلیل، مهندسی پرامپت به عنوان یک مهارت مهم در حوزه هوش مصنوعی شناخته میشود.
به عنوان مثال، در تحقیقات اخیر مشخص شده که استفاده از عباراتی مانند "نفس عمیق بکش و گام به گام این مسئله را حل کن" میتواند به مدل کمک کند تا پاسخهای دقیقتری ارائه دهد. این نشان میدهد که زبان و نحوه بیان درخواستها تأثیر زیادی بر کیفیت خروجی مدل دارد.
امبدینگ (Embedding)
امبدینگ نمایشهای عددی از متن، تصویر یا ویدئو هستند که روابط بین ورودیها را ثبت میکنند. به عنوان یک توسعهدهنده جاوا که به حوزه هوش مصنوعی میپردازد، نیازی نیست که تئوریهای پیچیده ریاضی یا پیادهسازیهای خاص این نمایشهای برداری را بهطور کامل درک کنید. یک درک پایه از نقش و عملکرد آنها در سیستمهای هوش مصنوعی کافی است، بهویژه زمانی که قصد دارید قابلیتهای هوش مصنوعی را در برنامههای خود ادغام کنید. امبدینگ با تبدیل متن، تصویر و ویدئو به بردارهایی از اعداد اعشاری که به آنها بردار (vector) میگویند، کار میکنند. این بردارها برای ثبت معنا و مفهوم متن، تصاویر و ویدئوها طراحی شدهاند. طول این بردارها به عنوان بُعد بردار (dimensionality) شناخته میشود.
مثلاً، اگر دو جمله دارای معنای مشابهی باشند، امبدینگهای آنها نیز به هم نزدیک خواهند بود. این نزدیکی با استفاده از محاسبه فاصله بین دو بردار در فضای چندبعدی تعیین میشود. این ویژگی به مدلهای هوش مصنوعی کمک میکند تا شباهت معنایی بین ورودیهای مختلف را تشخیص دهند و از این طریق به درک عمیقتر از متن دست یابند.
امبدینگها به ویژه در کاربردهای عملی مانند (Retrieval Augmented Generation - RAG) بسیار مفید هستند. در این الگو، امبدینگها به عنوان نقاطی در یک فضای معنایی چندبعدی عمل میکنند که شباهتها و روابط معنایی بین دادهها را نشان میدهند. برای مثال، در یک سیستم پرسش و پاسخ، امبدینگها میتوانند برای یافتن بخشهای مرتبط از مستندات که به پرسش کاربر پاسخ میدهند، استفاده شوند.

پایگاه دادههای برداری (Vector Databases)
پایگاه دادههای برداری به توسعهدهندگان اجازه میدهند تا دادههای برداری را ذخیره و بازیابی کنند. این دادهها که شامل امبدینگهای متن، تصویر یا ویدئو هستند، به عنوان نقاطی در یک فضای چندبعدی ذخیره میشوند. این پایگاه دادهها میتوانند به سرعت بردارهایی که بیشترین شباهت به بردار ورودی دارند را پیدا کنند که این برای کاربردهای مرتبط با جستجوی معنایی و بازیابی اطلاعات بسیار اهمیت دارد.
برای مثال، فرض کنید که یک کاربر به دنبال مستندات مرتبط با موضوع خاصی است. با استفاده از امبدینگها، میتوان هر مستند را به یک بردار تبدیل کرد و سپس از پایگاه داده برداری برای یافتن مستنداتی که بیشترین شباهت معنایی به پرسش کاربر دارند، استفاده کرد. این فرآیند به سیستمهای هوش مصنوعی کمک میکند تا پاسخهای دقیقتری ارائه دهند و اطلاعات مرتبطتری را بازیابی کنند.
یکی دیگر از کاربردهای پایگاه دادههای برداری در سیستمهای توصیهگر (Recommendation Systems) است. برای مثال، یک فروشگاه آنلاین میتواند از امبدینگها برای نمایش محصولات مشابه به کاربران استفاده کند. با تبدیل ویژگیهای هر محصول به بردار و ذخیره آنها در پایگاه داده برداری، سیستم میتواند محصولاتی که بیشترین شباهت را به محصولات مورد علاقه کاربر دارند، شناسایی و پیشنهاد دهد.
استفاده از پایگاه دادههای برداری به همراه امبدینگها به توسعهدهندگان این امکان را میدهد که سیستمهای هوشمندی بسازند که قادر به درک و تحلیل معنایی دادهها هستند و میتوانند تجربه کاربری بهتری را فراهم کنند.
توکنها (Tokens)
توکنها بلوکهای سازندهای هستند که مدلهای هوش مصنوعی برای پردازش ورودی و تولید خروجی از آنها استفاده میکنند. در واقع، مدلها با تبدیل کلمات به توکنها، ورودیها را تحلیل میکنند و سپس با تبدیل مجدد توکنها به کلمات، پاسخهای خود را تولید میکنند. به طور کلی، یک توکن میتواند به معنای یک کلمه، بخشی از یک کلمه یا حتی یک نشانهگذاری باشد.
به عنوان مثال، در زبان انگلیسی، یک توکن معمولاً حدود 75 درصد از یک کلمه را پوشش میدهد. برای مقایسه، کل آثار شکسپیر شامل حدود 900 هزار کلمه است که به تقریباً 1.2 میلیون توکن تبدیل میشود.
یکی از جنبههای مهم در کار با توکنها، هزینه پردازش آنها است. در مدلهای هوش مصنوعی مبتنی بر میزبانی، هزینهها بر اساس تعداد توکنهای استفاده شده تعیین میشود. هرچه تعداد توکنهای ورودی و خروجی بیشتر باشد، هزینه پردازش نیز بیشتر خواهد بود. علاوه بر این، مدلها دارای محدودیت تعداد توکن هستند که به عنوان "پنجره متنی" (context window) شناخته میشود. این محدودیت تعیین میکند که مدل تا چه میزان متن را در یک درخواست پردازش کند. به عنوان مثال، ChatGPT 3 دارای محدودیت 4 هزار توکن است، در حالی که GPT-4 گزینههایی با 8 هزار، 16 هزار و حتی 32 هزار توکن را ارائه میدهد.
خروجی ساختاریافته (Structured Output)
خروجی ساختاریافته به نوعی از خروجی مدلهای هوش مصنوعی اشاره دارد که به جای متن ساده، به صورت دادهای ساختاریافته ارائه میشود. این نوع خروجی برای توسعهدهندگان بسیار کاربردی است، زیرا به آنها اجازه میدهد تا به راحتی اطلاعات تولید شده توسط مدل را در سیستمهای خود ادغام کنند.
معمولاً مدلهای هوش مصنوعی خروجیهای خود را به صورت رشتهای از نوع java.lang.String تولید میکنند، حتی اگر از آنها خواسته شود که خروجی به فرمت JSON باشد. این خروجی ممکن است شبیه به یک JSON صحیح باشد، اما همچنان یک رشته متنی است و نه یک ساختار دادهای واقعی. به همین دلیل، برای استفاده از این خروجی در برنامهها، نیاز به پردازش و تبدیل آن به ساختارهای دادهای قابل استفاده مانند JSON یا دیگر قالبهای دادهای وجود دارد.
معماری تبدیل خروجی ساختاریافته به طور معمول شامل استفاده از پرامپتهای خاص است که مدل را به سمت تولید خروجی مورد نظر هدایت میکنند. این فرآیند ممکن است نیازمند چندین تعامل با مدل باشد تا خروجی به فرمتی که برای برنامه مناسب است، برسد.
برای مثال، یک پرامپت میتواند مدل را به تولید دادههایی در قالبی خاص هدایت کند، و سپس از یک مبدل برای تبدیل رشته خروجی به یک ساختار دادهای استفاده شود که برای برنامه کاربردی مناسب باشد. Spring AI با فراهم کردن ابزارهایی برای تعریف و مدیریت این نوع پرامپتها و همچنین تبدیل خروجی به ساختار دادهای مناسب، فرآیند تولید خروجی ساختاریافته را سادهتر میکند.

انتقال دادهها و APIها به مدل هوش مصنوعی (Bringing Your Data & APIs to the AI Model)
یکی از چالشهای اصلی در استفاده از مدلهای هوش مصنوعی، امکان ادغام دادههای سازمانی و APIهای موجود با این مدلها است. مدلهای مانند GPT-3 و GPT-4 تنها با دادههایی که تا زمان آموزششان در اختیار داشتهاند، کار میکنند و دسترسی مستقیم به دادههای جدیدتر یا دادههای خاص شما را ندارند.
برای این که مدل هوش مصنوعی بتواند از دادههای جدید استفاده کند، سه روش اصلی وجود دارد:
تنظیم مجدد (Fine Tuning): این روش شامل تغییر وزنهای داخلی مدل برای تطبیق با دادههای خاص شما است. این فرآیند برای متخصصان یادگیری ماشین پیچیده و همچنین برای مدلهای بزرگ مانند GPT بسیار پرهزینه است. علاوه بر این، برخی از مدلها ممکن است اصلاً این امکان را نداشته باشند.
پرامپتگذاری (Prompt Stuffing): در این روش، دادههای شما بهصورت مستقیم در پرامپت قرار میگیرد و به مدل ارائه میشود. با توجه به محدودیت تعداد توکنها، نیاز به تکنیکهای خاصی برای مدیریت دادههای مرتبط در داخل پنجره متنی مدل وجود دارد. Spring AI با ارائه ابزارهایی برای پیادهسازی این روش، فرآیند ادغام دادهها را ساده میکند.
فراخوانی تابع (Function Calling): این روش به شما اجازه میدهد تا توابع سفارشی خود را ثبت کنید و مدلهای زبان بزرگ را به APIهای سیستمهای خارجی متصل کنید. این توابع میتوانند به مدل امکان دسترسی به دادههای جدید و انجام عملیات پردازش داده را بدهند. Spring AI کد مورد نیاز برای پشتیبانی از فراخوانی توابع را بسیار سادهتر میکند و مدیریت این گفتگوها را برای شما برعهده میگیرد.
روش فراخوانی توابع بهویژه برای کاربردهایی که نیاز به تعامل مستقیم مدل با سیستمهای خارجی دارند بسیار مفید است. به عنوان مثال، اگر مدل نیاز داشته باشد که دادههای بهروز را از یک پایگاه داده استخراج کند یا اقدام خاصی را در سیستم شما انجام دهد، میتوانید از این روش بهره بگیرید.
در Spring AI، شما میتوانید توابع مورد نظر خود را بهصورت یک @Bean تعریف کنید و سپس نام آن تابع را در گزینههای پرامپت قرار دهید تا فعال شود. علاوه بر این، امکان تعریف و استفاده از چندین تابع در یک پرامپت نیز وجود دارد که این قابلیت به شما اجازه میدهد تا وظایف پیچیدهتری را به مدل محول کنید.

تولید تقویتشده با بازیابی (Retrieval Augmented Generation - RAG)
تولید تقویتشده با بازیابی (RAG) یک روش ترکیبی است که در آن مدلهای هوش مصنوعی از دادههای ذخیرهشده در پایگاه دادههای خارجی استفاده میکنند تا پاسخهای دقیقتر و بهتری تولید کنند. این روش به ویژه زمانی مفید است که مدل به دادههای بهروز و خاصی نیاز دارد که در زمان آموزش مدل در دسترس نبودهاند.
در RAG، مدل ابتدا از یک پایگاه داده برداری برای بازیابی اطلاعات مرتبط استفاده میکند و سپس این اطلاعات را به عنوان ورودی به مدل تولید متن میدهد تا پاسخ نهایی تولید شود. این روش به مدل امکان میدهد که به دانش بیشتری دسترسی داشته باشد و به سوالات پیچیدهتر و دقیقتری پاسخ دهد.
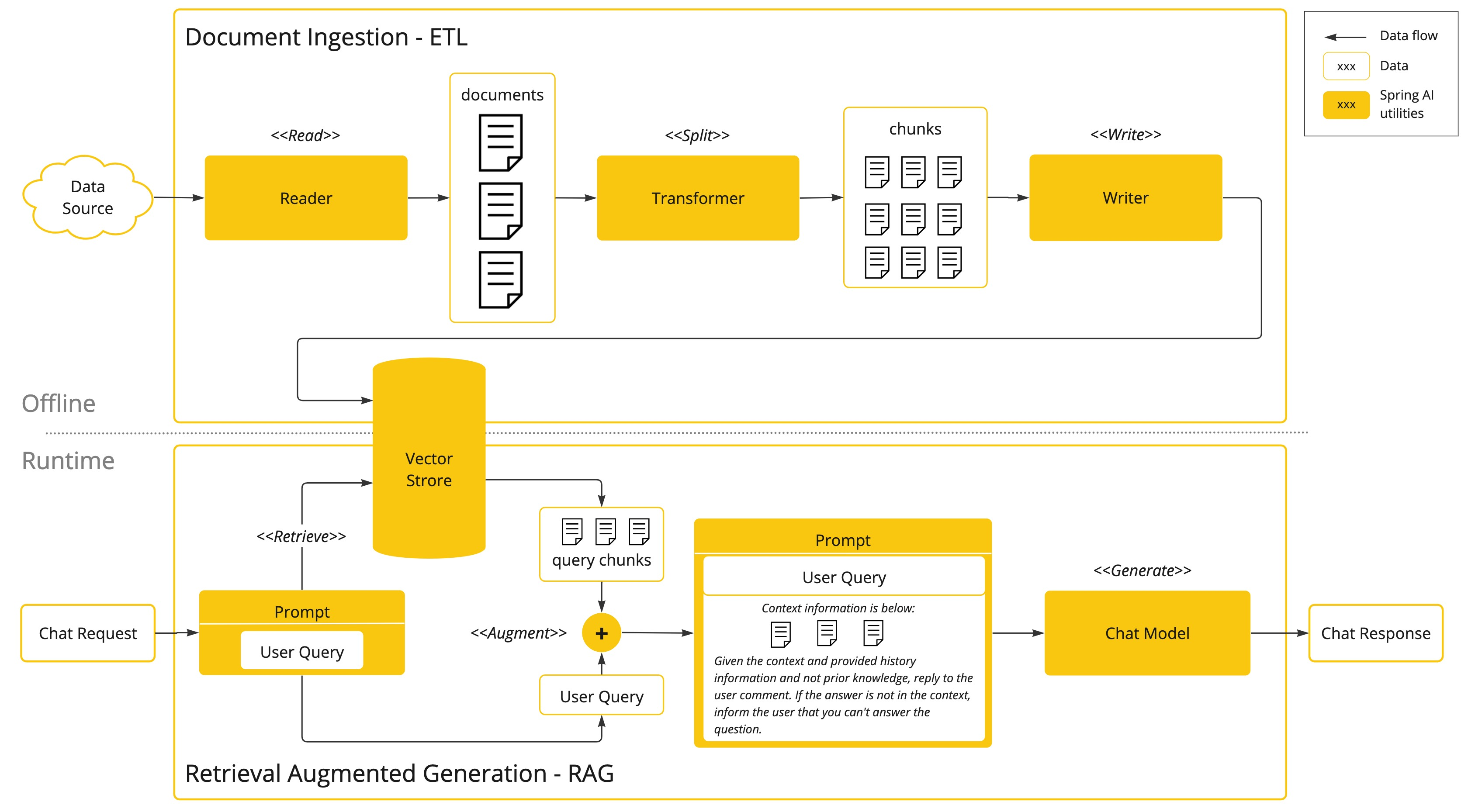
برای مثال، در یک سیستم پرسش و پاسخ، ابتدا سوال کاربر به عنوان ورودی به پایگاه داده برداری داده میشود تا مستندات مرتبط بازیابی شوند. سپس این مستندات به عنوان زمینه به مدل داده میشوند تا پاسخ نهایی تولید شود. این فرآیند شامل دو مرحله اصلی است: بازیابی اطلاعات مرتبط و تولید پاسخ بر اساس اطلاعات بازیابی شده. این ساختار به مدل امکان میدهد که به دادههای جدید و خاص دسترسی پیدا کند و پاسخهای بهتری ارائه دهد.
شکل بالا نشاندهنده معماری RAG است که شامل مراحل مختلفی از جمله استخراج دادهها، بازیابی اطلاعات مرتبط و تولید پاسخ نهایی میباشد. در این معماری، ابتدا دادهها از منابع مختلف خوانده شده و به صورت قطعات کوچکتر تبدیل میشوند. این قطعات به پایگاه داده برداری وارد میشوند و در زمان درخواست کاربر، اطلاعات مرتبط بازیابی و به مدل ارائه میشود تا پاسخ نهایی تولید شود.
فراخوانی توابع (Function Calling)
فراخوانی توابع یکی از روشهای کارآمد برای ادغام مدلهای هوش مصنوعی با سیستمهای خارجی است. این روش به شما اجازه میدهد که توابع خاصی را تعریف کنید و به مدل اجازه دهید تا از این توابع استفاده کند تا با APIهای خارجی یا سیستمهای دیگر ارتباط برقرار کند.
در این روش، مدل میتواند به جای تولید پاسخهای متنی ساده، با توابع ثبتشده ارتباط برقرار کرده و عملیات خاصی را انجام دهد. برای مثال، شما میتوانید توابعی را برای بازیابی اطلاعات از پایگاه داده، ارسال ایمیل، یا انجام عملیات محاسباتی تعریف کنید و سپس از مدل بخواهید که در صورت لزوم این توابع را فراخوانی کند.
Spring AI با استفاده از قابلیت فراخوانی توابع به توسعهدهندگان امکان میدهد تا وظایف پیچیدهای را به صورت پویا مدیریت کنند. این قابلیت به شما اجازه میدهد تا توابع را به صورت یک @Bean تعریف کرده و سپس آنها را در پرامپتهای خود به کار ببرید. به این ترتیب، مدل میتواند به راحتی با سیستمهای مختلف ارتباط برقرار کرده و وظایف مورد نیاز را انجام دهد.
فراخوانی توابع به ویژه در مواردی که نیاز به انجام اقدامات خاصی مانند بهروزرسانی دادهها، انجام محاسبات پیچیده، یا ارتباط با سرویسهای خارجی دارید، بسیار کاربردی است. این روش به مدل امکان میدهد که نه تنها پاسخهای متنی ارائه دهد، بلکه به صورت فعال به انجام وظایف خاص نیز بپردازد.

شکل بالا نحوه عملکرد فراخوانی توابع را نشان میدهد. در این فرآیند، ابتدا پرامپت حاوی تعریف تابع ارسال میشود (مرحله 1). این تعریف شامل نام، توضیحات و ورودیهای تابع است. سپس مدل تصمیم میگیرد که آیا باید تابع را فراخوانی کند یا خیر (مرحله 2). اگر مدل تصمیم به فراخوانی تابع بگیرد، درخواست به رجیستری تابع در Spring AI ارسال میشود (مرحله 3) و تابع مورد نظر اجرا میشود. نتیجه اجرای تابع به مدل بازگردانده میشود (مرحله 4) و در نهایت مدل از این نتیجه برای تولید پاسخ نهایی استفاده میکند (مرحله 5).
مدلهای زبان بزرگ (LLMs) پس از آموزش ثابت میمانند و قادر به دسترسی یا تغییر دادههای خارجی نیستند. مکانیزم فراخوانی توابع این محدودیت را برطرف میکند. این مکانیزم به شما اجازه میدهد توابع خود را برای اتصال مدلهای زبان بزرگ به APIهای سیستمهای خارجی ثبت کنید. این سیستمها میتوانند دادههای بلادرنگ را به مدلهای LLM ارائه دهند و عملیات پردازش داده را به نمایندگی از آنها انجام دهند.
Spring AI فرآیند فراخوانی توابع را برای شما سادهتر میکند و به شما اجازه میدهد تا به راحتی توابع را به عنوان @Bean تعریف کرده و از آنها در پرامپتهای خود استفاده کنید. همچنین میتوانید چندین تابع را در یک پرامپت تعریف و ارجاع دهید و مدل میتواند برای دریافت تمامی اطلاعات مورد نیاز، چندین فراخوانی تابع انجام دهد. پس از کسب تمامی اطلاعات لازم، مدل پاسخ نهایی را تولید میکند.
ارزیابی پاسخهای هوش مصنوعی (Evaluating AI responses)
ارزیابی مؤثر خروجیهای یک سیستم هوش مصنوعی در پاسخ به درخواستهای کاربر بسیار مهم است تا از دقت و مفید بودن برنامه نهایی اطمینان حاصل شود. تکنیکهای نوظهوری وجود دارند که امکان استفاده از مدل پیشآموزشیافته را برای این منظور فراهم میکنند.
این فرآیند ارزیابی شامل تحلیل این است که آیا پاسخ تولید شده با نیت کاربر و زمینه پرسش همخوانی دارد یا خیر. معیارهایی مانند مرتبط بودن، انسجام و صحت واقعی برای ارزیابی کیفیت پاسخهای تولید شده توسط هوش مصنوعی استفاده میشوند.
یک رویکرد این است که درخواست کاربر و پاسخ مدل هوش مصنوعی را به مدل ارائه داده و پرسید که آیا پاسخ با دادههای ارائه شده همخوانی دارد یا خیر.
علاوه بر این، استفاده از اطلاعات ذخیرهشده در پایگاه داده برداری به عنوان دادههای مکمل میتواند فرآیند ارزیابی را بهبود بخشیده و در تعیین مرتبط بودن پاسخ کمک کند.
پروژه Spring AI یک API ارزیاب (Evaluator API) ارائه میدهد که در حال حاضر به استراتژیهای پایهای برای ارزیابی پاسخهای مدل دسترسی میدهد. برای اطلاعات بیشتر به مستندات تست ارزیابی مراجعه کنید.